
1·
4 days agoBecause it has integrations for The Internet Archive: https://x0.at/Wny_.png
It says “local html” but I have a feeling it simply grabs a copy from the internet archive. I can’t even find where its storing these copies with it enabled.
Because it has integrations for The Internet Archive: https://x0.at/Wny_.png
It says “local html” but I have a feeling it simply grabs a copy from the internet archive. I can’t even find where its storing these copies with it enabled.
The same way you do any other project. If you’re interested, you go looking. You find my project which has a link to the repo. A link is a link. You’re simply fighting over where the link goes to, and I’m pointing out that it’s a stupid argument to be had.
Github is an important resource.
And there’s dozens and dozens of replacements available. The issue you’re speaking of isn’t an issue with Github at all. It’s an issue with developers.
If Github going off the map borks your development because PROGRAMMERS can’t use anything but Github, you have much bigger problems than you think.
There is. wget doesn’t follow recursive links by default. If it is, you’re using an option which is telling it to…
It does neither. It doesn’t create snapshots of pages at all… It’s a bookmark manager.

If there’s one thing you want in a website used by almost 75 million beneficiaries it’s a platform hastily put together by a crack team of geniuses–that don’t password protect databases–“in months.”
This is gonna go very very very poorly.
https://linkding.link/ is what you’re looking for.
Use the bookmarklet or FF/Chrome extension on a page and it saves it to your server to look at later. Add tags, folders, whatever. You can setup newly added links to be un-archived, and old links to be archived, or basically however you want.
I think you’re kind of missing the point of OSS. Github could completely fall off the face of the earth tomorrow and nothing bad happens. There are dozens of other platforms to facilitate the development of software online. Github is not the end all be all and in the grand scheme is only a small player.
That’s not a bug. You literally told wget to follow links, so it did.
restic restore --dry-run
Great work man. That’s really the only thing that I’ve found to gripe about. Other than that it was a simple setup and configuration. I particularly like that you hold my hand when changing things like the font. Such a subtle but cool change to add some individuality to it.
Great tool. I just pushed it to production for all my projects.
Doesn’t support docker host names, which is a bummer. You have to use IPv4/6 and the docker IP for services to work correctly. The service setup is also a bit weird. You can’t seem to delete a service once it’s been made. You can only “hide” it. So I just set this up, and mistyped an IP, and now I have a service with only 70% uptime because the first few pings failed due to the mistyped IP. (https://x0.at/ZvM1.png) There doesn’t seem to be a way to reset the uptime, or delete the monitor. You actually have to rename the service monitor to something random, and “hide” it, then remake your service like new.
Seems weird.
Nice dashboard though.
bookmarks
low on disk space
Goddamn boy, how many links you got? A million? lol
wget is the most comprehensive site cloner there is. What exactly do you mean by complex? Because wget works for anything static and public… If you’re trying to clone compiled source files, like PHP or something, obviously that’s not going to work. If that’s what you mean by “complex” then just give up, because you can’t.
wget.
Everything seems fine with 1.39.1. What’s the docker log say? Also which version?
Sure, you can also do this. But why not make it available to your network in addition to Jellyfin? What if you have a TV that doesn’t have access to the Jellyfin app? If it’s a private ZFS pool not on the network you’re fucked. If you share the media via a network share, you can always do any number of things to stream that media to your TV.
It gives you a ton more options up to and including just watching the media on your PC in your favorite media browser.
TrueNAS is not absolutely required.
It just seems to be the favorite. Anything would work. OMV, EasyNAS, OpenFiler, Rockstor, even just base *nix with the appropriate packages and config.
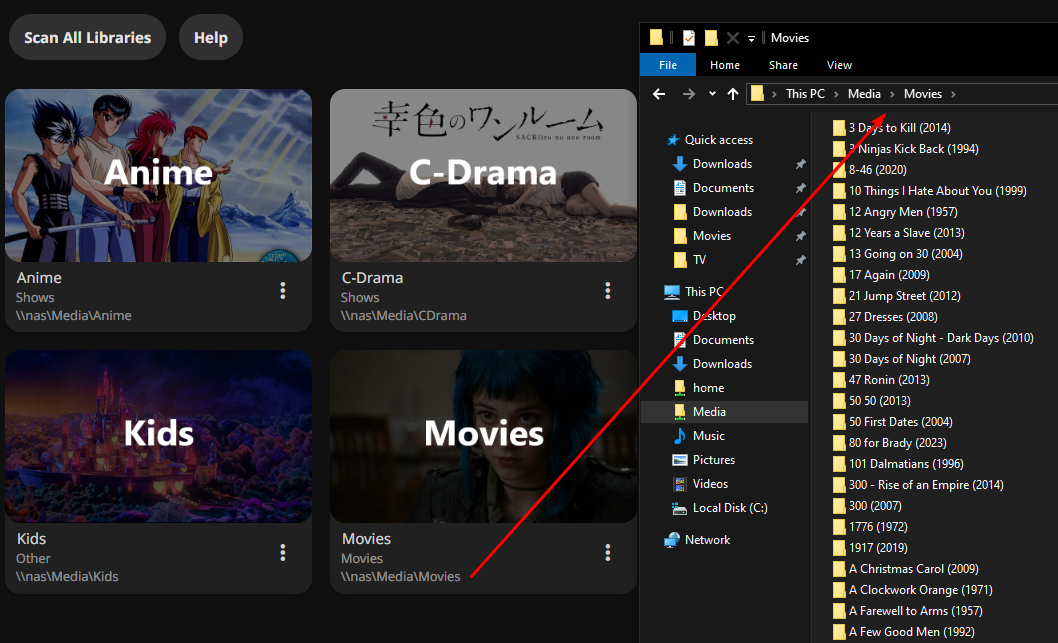
You’d create a ZFS pool for your shares, then a TrueNAS VM which serves your ZFS pool as NAS. Then setup your Jellyfin VM using your NAS as storage for your libraries. Ends up looking like this: https://x0.at/Gbqm.png
Your media is accessible via the network from any device because they’re SMB shares, and it works just fine in Jellyfin. If you only create a ZFS pool for Jellyfin, your media can then only be accessed through Jellyfin. It limits your future options.

{kind=link}
{kind=link}
{kind=link}
It’s likely illegal. The administration would call it theft of service because it’s not authorized and they wouldn’t be wrong. I also don’t see why you would want to do it. You’re giving the IT department at your school complete access to your web history.