- 12 Posts
- 10 Comments

 14·9 days ago
14·9 days agoIP based blocking is complicated once you are big enough
It’s literally as simple as importing an ipset into iptables and refreshing it from time to time. There is even predefined tools for that.
While AI crawlers are a problem I’m also kind of astonished why so many projects don’t use tools like ratelimiters or IP-blocklists. These are pretty simple to setup, cause no/very little additional load and don’t cause collateral damage for legitimate users that just happend to use a different browser.
 9·9 months ago
9·9 months agoWell from my personal PoV there are a few problems with that
- You can’t detect all credentials reliably, they could be encoded in base64 for example
- I think it’s kind of okay to commit credentials and configuration used for the local dev environment (and ONLY the local one). E.g. when you require some infrastructure like a database inside a container for your app. Not every dev wants to manually set a few dozen configuration entries when they quickly want to checkout and run the app
I also personally ask myself how a PyPI Admin & Director of Infrastructure can miss out on so many basic coding and security relevant aspects:
- Hardcoding credentials and not using dedicated secret files, environment variable or other secret stores
- For any source that you compile you have to assume that - in one way or another - it ends up in the final artifact - Apparently this was not fully understood (“.pyc files containing the compiled bytecode weren’t considered”)
- Not using a isolated build process e.g. a CI with an isolated VM or a container - This will inevitable lead to “works on my machine” scenarios
- Needing the built artifact (containerimage) only locally but pushing it into a publicly available registry
- Using a access token that has full admin permissions for everything, despite only requiring it to bypass rate limits
- Apparently using a single access token for everything
- When you use Git locally and want to push to GitHub you need an access token. The fact that article says “the one and only GitHub access token related to my account” likely indicates that this token was at least also used for this
- One of the takeaways of the article says “set aggressive expiration dates for API tokens” - This won’t help much if you don’t understand how to handle them properly in the first place. An attacker can still use them before they expire or simply extract updated tokens from newer artifacts.
On the other hand what went well:
- When this was reported it was reacted upon within a few minutes
- Some of my above points of criticism now appear to be taken into account (“Takeaways”)
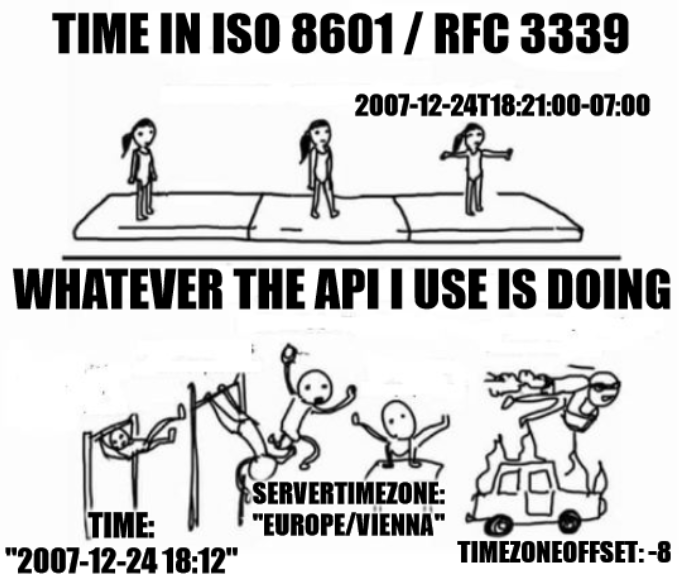
Just for further clarification, the API works like this:
timeis the local (client) time (in this case UTC-7)servertimezoneis the time zone where the server is locatedtimezoneoffsetis the offset of the local time relative to the servertimezone (offset from the servers PoV)
To get the UTC date you have to do something like this:
time.minusHours(timezoneoffset).atZone(servertimezone).toUTC()
Well if it’s a 32bit timestamp you’re screwed after 19 January 2038 (at 03:14:07 UTC)
So just for additional context:
This meme was brought to you by the following API response scheme:
{ "time": "2007-12-24 18:12", "servertimezone": "Europe/Vienna", "timezoneoffset": -8 }when it could have just been
{ "date": "2007-12-24T18:21:00-07:00" }
If you use utc here and a time zone definition changes, you’re boned
I’m pretty sure that things like the tz database exist exactly for such a case.
As far as I can tell it’s the other ways around: IPv4 is getting more costly
Example: AWS started to charge for IPv4 addresses a few months ago - a IPv4 address now costs around $3.6 per month

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Can’t wait for all the other horror stories getting posted here :D