

26·
8 days agoLet’s just say there was more than one cow that jumped over the moon…
Let’s just say there was more than one cow that jumped over the moon…
How is there not a thin sheen of Cheeto dust or kebab juice over any of that. What kind of madman is this?
I only know that Marvell is bad, are the rest also bad?
why would you hurt me like this
Is the guy in the background 69ing a Tuba
therefore a computer must always
kick a figurative dick
cd ~/repos/work-project27
git checkout dev
git branch new_feature
### code for a few hours, close laptop, go to sleep, next morning
git checkout dev
### code for a few more hours, close laptop go to sleep, next morning
## "oh fuck, I already implemented this in new_feature but differently"
git checkout dev
git diff new_feature
## "oh no. oh no no no. oh fuck. I can't merge any of this upstream and my history is borked."
git clone git@workhub:work/work-project work-project28
cd ~/repos/work-project28

I was gonna say, really? AI to parse a timeline? Overkill
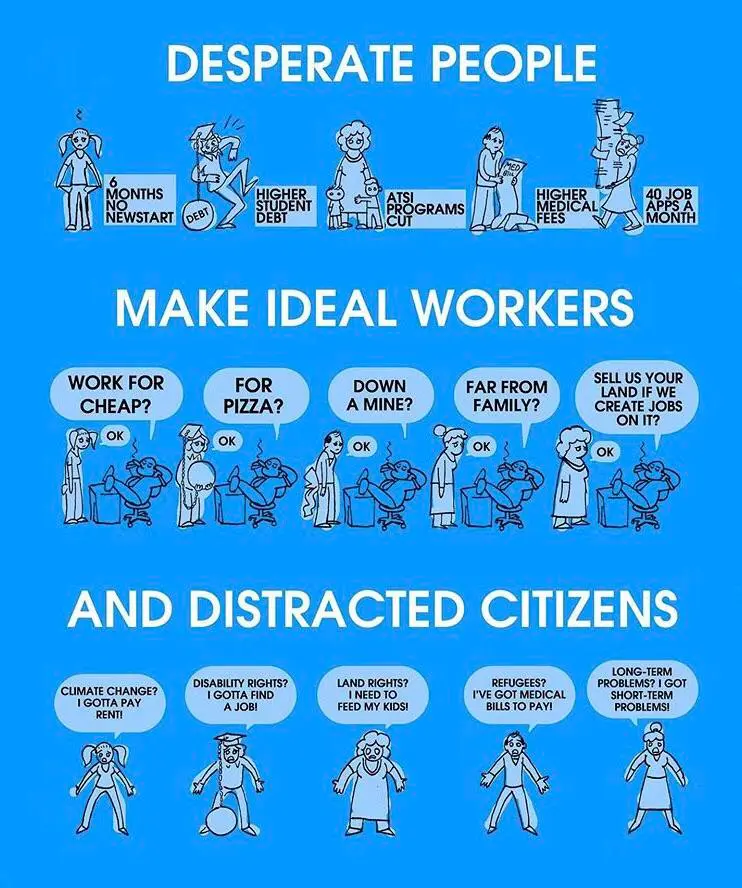
it could turn violent and do real damage to capital, that’s the beauty of an unfocused protest – the night is ever young
“We saw a blip in <sale/metric/police safety> and we think it correlates with the general unhappiness of the populace, as displayed here, here, and maybe here.”
Blips can cause panic, even small ones
with no cohesive objectives
That’s a pro. As soon as there’s a clear motif or leader, it’s very easy to undermine that single point of weakness. A general rabble sends the clear vibe of “we are not impressed, and might burn things” with the air of uncertainty to keep the powers that be on their toes.
We should make it April 30th, because that way if no one receives their propers, then the developers can go on the strike the day after.

Its just easy to write super-optimised code snippets in without having to break out into assembly.
When you download R, youre downloading C++/C and Fortran
I have to admit, PDF parsing being such a hot and profitable topic in computer science was really something I never saw coming.
PDFs? The things you can select text from? And when not, there’s decent OCR? And when not, you just ask the person to send you an email or a word doc?
It sounds like LLMs are looking for a new unpolluted source of historical data that they can learn from, and this source exists in the form of old scanned-in paper documents. That’s the only reason I can fathom as to why this is such a big thing now.
my computer lives inside my keyboard, next to the keyboard’s computer
Ah okay. I think my accusatory point still stands, albeit with the “you” now generalised as “you all”. I’m good at making friends.


{kind=link}
I prefer this default. Im sick of having to rein in Numba cores or OpenBlas threads or other out of control software that immediately tries to bottleneck my stack.
CGroups (Docker/LXC) is the obvious solution, but it shouldn’t have to be