

7·
10 hours agoCan you elaborate in detail on what makes it “toy shaped?”


If you didn’t get the memo about marketing targeting, there are courses for that. You can drop the sarcasm.

Programmer and sysadmin (DevOps?), wannabe polymath in tech, science and the mind. Neurodivergent, disabled, burned out, and close to throwing in the towel, but still liking ponies 🦄 and sometimes willing to discuss stuff.
Can you elaborate in detail on what makes it “toy shaped?”
If you didn’t get the memo about marketing targeting, there are courses for that. You can drop the sarcasm.
If you don’t want to use AI in WhatsApp, make sure you keep your hands off the AI button that appears right above the new chat button
There, that’s how you turn it off: exert self-control.
Red herring. QDs are not a measure of display quality. These ones are:
Add power usage and price, and I couldn’t care less about it being CRT, TFT, IPS, OLED, QLED, Laser, or hologram.
I’m not into nicotine (menthol extra cold nasal cleaning is my thing), and after comparing prices… went with the 100% modular Vaporesso: mod, pod, coil, custom juice. Initially it’s slightly more expensive, but pods last forever, grabbed some coil packs at a good discount which pretty much offset the rest, and after almost a year still haven’t gone through a full bottle of juice.
In EU, Spain in particular, we get 3 years of warranty on customer devices, so the mod itself better last that long!
Not exactly. Toy-shaped non-nicotine fruit-flavored cheap disposables, are the best thing to get children hooked up on vaping.
Tobacco companies used to promote candy cigarettes for the same purpose.
They’re not. Check those laws again, only nicotine ones are banned.
Android is Android/Linux, not GNU/Linux.
The Linux kernel is compatible with a closed source userland, what makes GNU/Linux attract the userland towards open source, is GNU’s glibc, other libc alternatives don’t have that effect.
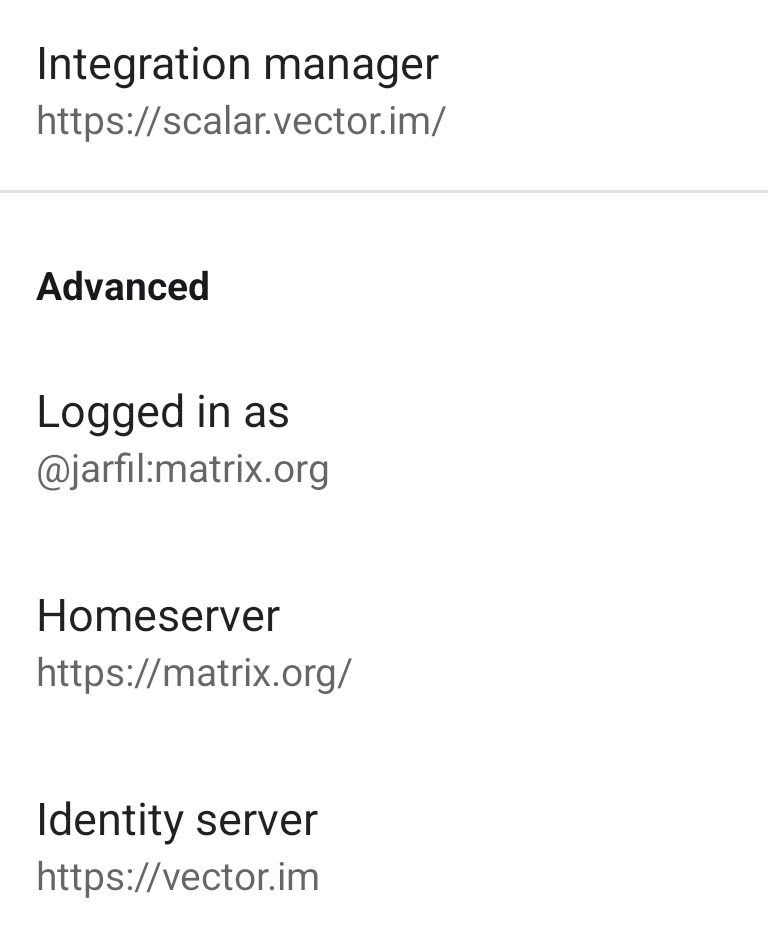
Matrix/Element allows for mixing different servers for each part of the stack:
GOOGL knows that to become a long term successful company in a world of 4.50% interest rates, that P/E of 21 and dividend yield of 0.49% are barely cutting it.
They can no longer push popular platforms like YouTube as a loss leader.

Depends… I’ve been running 2.99 for a while now 😄
Oooooh, can’t wait to see the new features!
[what? there is no new features…?]
Can’t wait to see the new splash screen! 😇
A company that can’t offer a ROI to its stockholders, is a startup that should never be allowed to go public; stick to angel and venture investors instead. Public stocks relying on the hype of “growing quickly”, are a Ponzi scheme through and through.
If we speak of company ages, the argument doesn’t hold either:
A good chunk of the US market is made up of Ponzi scheme companies. With 401k-s tied to market investments, people are setting themselves up for a very rough awakening.
Meaningful part are the dividend ratios.
The problem with P/E is that, while it’s great to measure business health internally, a company that has great earnings and then decides to “invest in growth” instead of paying dividends, is just a Ponzi scheme as far as investors are concerned: no expectation of returns from the company, only from the hype among other investors.
Is TSLA overvalued? To be generous, let’s compare them to just NASDAQ stocks:
When your Lemmy client shows you previews of the links…
The bill hasn’t passed yet, we’ll see what amendments get into the final version.
The general downside of this kind of bills, is that they require marking “any amount” of AI-based modification, like for example: using an “AI optimized” curves modifier to adjust a photo, makes the whole thing into “made using AI”.
My phone camera has an AI based detector for focusing on faces, pieces of paper, brightness and color correction… so ALL photos I take with it are automatically “made with AI”, which is BS.
Which one? It has several.
Whoever the fuck thought it would be a good idea to add a script tag to SVG needs to be put down.
SVG was in part intended as a replacement for Flash, which had animations and interactive graphic elements. The script tag has been there since 2001’s SVG 1.0 🤷
Not sure where you get your propaganda from, but I refuse to engage with that whole twisted argumental line. I stand by what I said, I think it was pretty straightforward.



{kind=link}
You call it “bullshit propaganda”, because you haven’t seen black market disposables from China advertised at you local vape shop? Have you considered that, maybe, you haven’t seen them… precisely because they were stopped at customs?
No, I’m not even going to look for a SKU listing, just for your dismissal. Go believe it’s FUD if that makes you happier. Ask your government agencies to lift all bans, for extra un-FUDding.